Intro to S3
The Simple Storage Service (S3) was one of the first services released by AWS in 2006. It was a trailblazing service that give developers an infinitly scalable storage repository, as long as they adapted to the unique way in which S3 works.
S3 has quickly grown into one of the largest cloud computing services in the world. AWS reports that there are trillions of objects stored in S3. Some of the largest websites on the interent, including customers like Dropbox use it to store their critical data.
Within the AWS ecosystem, S3 has become a critical storage service. It has many different use cases. Customers use it to host static assets such as images and videos. Because it's a reliable service, it is often used to store data backups. Customers who do large scalabe data computing use it in their workflow as they move data between compute nodes.
What is S3?
The simplest way to describe S3 is that it is an object storage service. It allows customers to upload data of any type. But it is very different than a harddrive. You can't mount S3 (natively) to a server, for example.
In this lesson we will take a look at some of the characteristics that make up S3.
Object Storage
This is perhaps one of the biggest difference between S3 and what is traditionally thought as storage infrastructure. There is no file system. You can't attach S3 to an EC2 instance (at least not natively).
Instead, you use the S3 interfaces to upload files. Those files are referred to as objects. And you can then access those files later on.
HTTP Access
Data is uploaded and downloaded to S3 using HTTP operations. Uploading data is a HTTP POST request. Downloading data is a HTTP GET request. That's how the service works.
Resilient Architecture
S3 was designed to be very resilient. AWS makes these stamenets about how resilient the service actually is:
- Designed to provide 99.999999999% durability
- Designed for 99.99% availability of objects over a given year
- Designed to sustain the concurrent loss of data in two facilities
In practice this means that chances are S3 will never lose one of your objects. Their track record has been very good, with few if any reports of data loss (although they have had service availability outages before).
Anatomy of S3
In this lesson we will take a closer look at how the S3 service works. Study the following diagram and then read the analysis below.
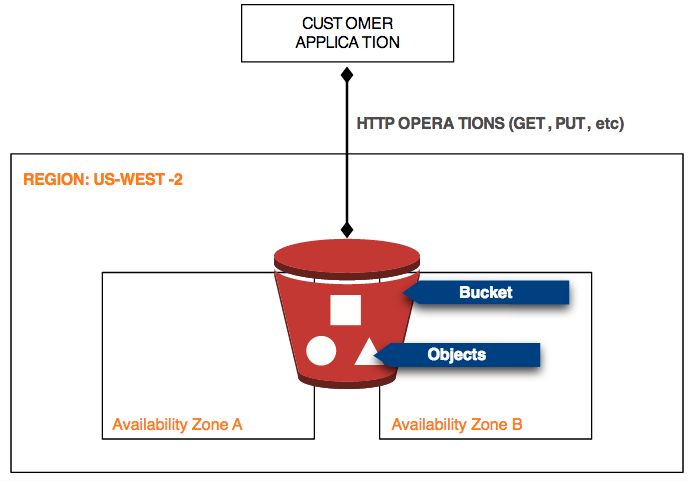
Region & Availability Zone
S3 was designed to provide a high level of data durability. They market the service is "designed for durability of 99.999999999% of objects". To translate this to something more tangible, AWS says:
"This durability level corresponds to an average annual expected loss of 0.000000001% of objects. For example, if you store 10,000 objects with Amazon S3, you can on average expect to incur a loss of a single object once every 10,000,000 years."
To achieve this, AWS takes these measures:
"[S3] stores your objects on multiple devices across multiple facilities in an Amazon S3 Region. The service is designed to sustain concurrent device failures by quickly detecting and repairing any lost redundancy. When processing a request to store data, the service will redundantly store your object across multiple facilities before returning SUCCESS. Amazon S3 also regularly verifies the integrity of your data using checksums."
When using S3 you have to select the Region to store your objects.
Buckets
S3 introduces the concepts of buckets. Buckets are like folders on your computer; they are a container for objects. The AWS Management Console even depicts the buckets as directories.
Note: An AWS can only have 100 buckets.
Objects
As mentioned before, objects are files that are uploaded to S3. These files can be anything. The only limitation is the file size.
HTTP APIs
Buckets and objects are managed using REST APIs. S3 publishes a list of accepted operations.
Access Control & Policies
S3 controls access to buckets and objects using Access Control Lists (ACLs) and policies. Both of these can allow or prevent access to data per your instructions.